When it comes to web crawlers, people often associate Python with crawling to some extent. This is fundamentally due to Python's rich ecosystem and its flexible, simple syntax. Additionally, there are several powerful crawling frameworks based on Python that greatly reduce the difficulty of crawling and improve the efficiency of writing programs. Recently, I also tried Scrapy, so I will make a record of my introduction.
Introduction#
Scrapy is an application framework for crawling websites and extracting structured data from them, which can be used for various useful applications such as data mining, information processing, or historical archiving.
——Translated from the official website
I recommend checking the official website directly, which even has a complete Scrapy tutorial, making it an essential choice for in-depth learning of the framework!
Installation#
There are many methods available online for installing the Scrapy framework. Depending on the Python environment, there may be some strange errors. Here, I am based on a Python 3 environment with pip pre-installed, and I have tested it successfully.
Pre-installed Environment
Windows 10 + Python 3.7.0 + pip 20.1 + virtualenv
Please also open a new virtual environment to ensure that there are no dependency conflicts with other packages.
Initial Component Installation
lxmlpyOpenSSLTwistedPyWin32
Installing lxml
You can install it directly using pip. This is a library for parsing HTML and XML in Python, which is often used even without a framework.
pip3 install lxml
Installing PyWin32
Download the corresponding version of the installation package from the official website and double-click to install pywin32.
Installing Remaining Components
First, let me introduce wheel.
wheel is a packaging format for Python. Previously, the mainstream packaging format for Python was .egg files, but now *.whl files have also become popular.
wheel is actually a compressed packaging component in Python, somewhat similar to zip files. However, in this article, you just need to know that you can quickly install a library into your Python environment using the wheel file format.
Installation is quite simple:
pip3 install wheel
Now your Python environment supports the installation of .whl file formats.
The next step is to download the whl format of each component from their respective official websites, ensuring compatibility with your Python environment.
Installation:
pip3 install pyOpenSSL-19.1.0-py2.py3-none-any.whl
TwistedMake sure it corresponds to your Python version.
For my environment, it is:
pip3 install Twisted-20.3.0-cp37-cp37m-win_amd64.whl
Installing Scrapy
Once all the dependency packages are successfully installed, you can directly install Scrapy using pip without any issues.
pip3 install Scrapy
Component Introduction#
First, create a project.
Run this in the folder where you want to place your crawler project, where xxx is your project name.
scrapy startproject xxx
Let’s also record some basic operations:
- Create a project:
scrapy startproject xxx - Enter the project:
cd xxx # Enter a specific folder - Create a spider:
scrapy genspider xxx (spider name) xxx.com (crawl domain) - Generate a file:
scrapy crawl xxx -o xxx.json (generate a specific type of file) - Run the spider:
scrapy crawl XXX - List all spiders:
scrapy list - Get configuration information:
scrapy settings [options]
After creation, you will see these contents in the folder:
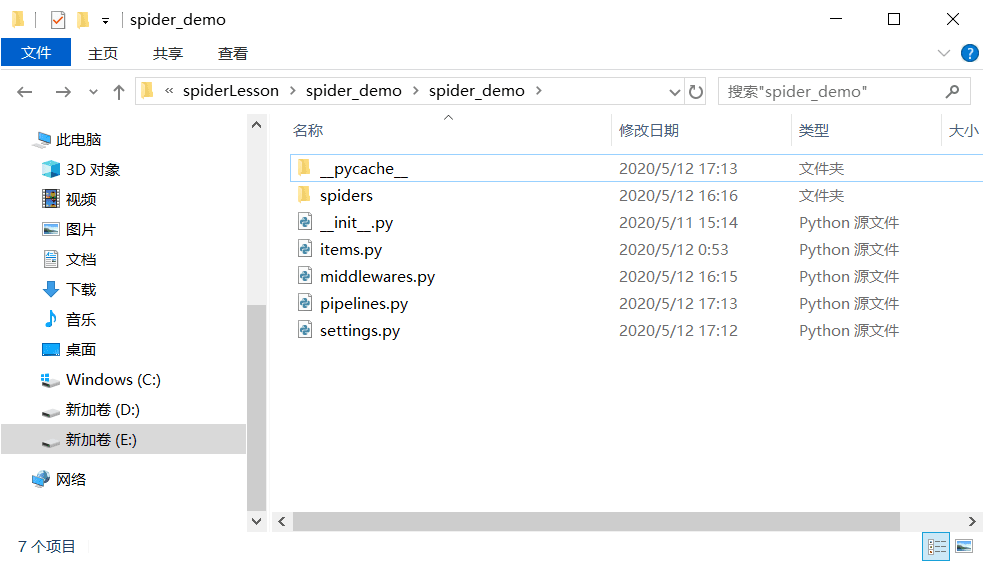
Let’s introduce these components one by one (spider_demo is your spider project name):
scrapy.cfg: The project's configuration file (in the parallel directory of the project folder)spider_demo/spiders/: The directory for placingspidercode. (Where the spider's specific logic is placed)spider_demo/items.py: Theitemfile in the project. (Where to create containers and define the format of the results obtained by the spider)spider_demo/pipelines.py: Thepipelinesfile in the project. (Implementing data cleaning, storage, and validation)spider_demo/settings.py: The project's settings file. (Specific configurations for the spider, including enabling or disabling certain middlewares and functionalities)spider_demo/middlewares.py: Defines the downloader and spider middlewares of the project.
Feeling a bit confused? Next, let’s briefly introduce the principles of how scrapy operates, which should help you better understand the roles of these components.
Flowchart from the official website
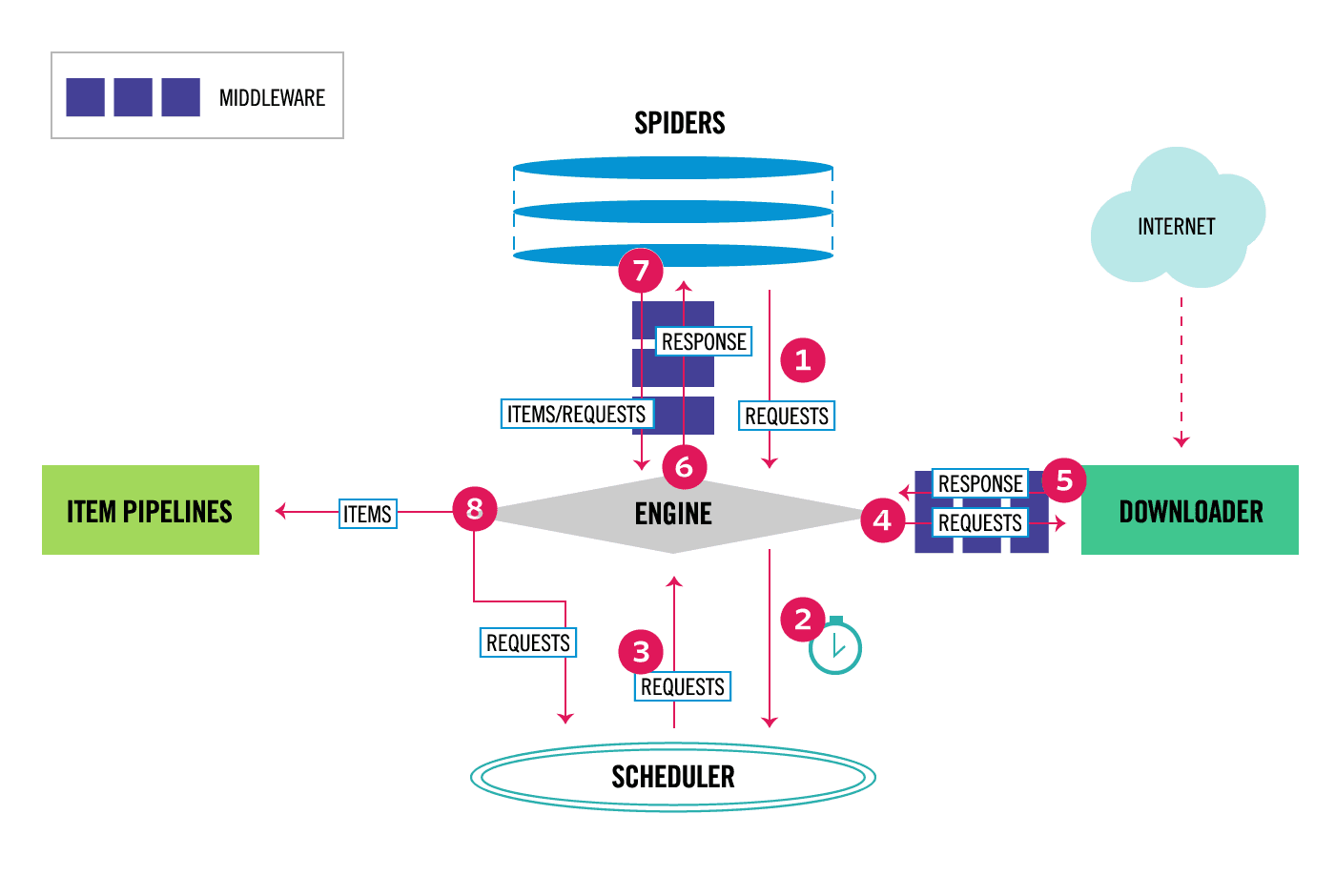
Scrapy is controlled by an execution engine.
Spidersends requests to theEngineEngineschedules requests to theSchedulerand accepts the next crawl requestSchedulerreturns the next requestEnginesends the request to theDownloaderthroughDownloader MiddlewaresDownloadercrawls the webpage and sends the returned result back to theEnginethroughDownloader Middlewares- The engine receives the response and forwards it to the
Spiderfor processing throughSpider Middleware - The
Spider'sparse()method processes the obtainedresponse, extractingitemsor requests, and returns the parseditemsor requests to theEngine - The
Enginesends theitemsto theItem Pipelineand sends the requests to theScheduler - Repeat step 1 until there are no new requests
Let’s summarize the components that appear in the above steps:
| Component Name | Component Function | |
|---|---|---|
| Engine | The core of the framework, responsible for overall data and signal scheduling | Framework Implementation |
| Scheduler | A queue for storing requests | Framework Implementation |
| Downloader | The unit that executes specific download tasks | Framework Implementation |
| Spider | Processes the response obtained from downloads, extracting the required data (specific business logic) | User Implementation |
| Item Pipeline | Processes the final obtained data, such as performing persistence operations | User Implementation |
| Downloader Middlewares | Allows for some custom processing before the actual download task. For example, setting request headers, setting proxies | User Implementation |
| Spider Middlewares | Customizes requests and filters responses | User Implementation |
I believe this set of combinations should give you a basic understanding of the framework. Next, let’s reinforce this memory through practical application.
Simple Application#
This time, I created a demo based on crawling the box office rankings from Maoyan. I will switch to a more complex demo when I have time.
The goal is to crawl the movie titles, scores, and rankings from the movie ranking list and save the results in a .json file format.
First, you need to determine what data you need to crawl and record the required data in the container, which you will write in item.py:
import scrapy
# Here we need ranking, title, number of collections, release time, and score
class SpiderDemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
index = scrapy.Field()
title = scrapy.Field()
star = scrapy.Field()
releasetime = scrapy.Field()
score = scrapy.Field()
Next, create a new spider file in the Spiders folder, for example, I created a MoyanSpider.py file.
import scrapy
from spider_demo.items import SpiderDemoItem
class MaoyanSpider(scrapy.Spider):
# This is the name of the spider when it starts, which will be used to start the spider later
name = "maoyan"
# List of allowed domains for crawling
allowed_domains = ["maoyan.com"]
# Target URLs to crawl
start_urls = [
"http://maoyan.com/board/7/",
"http://maoyan.com/board/4/",
]
# Handle the already downloaded pages
def parse(self, response):
dl = response.css(".board-wrapper dd")
# Parse to get specific data and store it in the container
for dd in dl:
item = SpiderDemoItem()
item["index"] = dd.css(".board-index::text").extract_first()
item["title"] = dd.css(".name a::text").extract_first()
item["star"] = dd.css(".star::text").extract_first()
item["releasetime"] = dd.css(".releasetime::text").extract_first()
score = dd.css('.integer::text').extract_first()
if score is not None:
item["score"] = score + dd.css('.fraction::text').extract_first()
else:
item["score"] = 0
# Return the result using yield
yield item
Here, it’s worth mentioning that scrapy supports various types of parsing. You can use the common three parsing libraries for parsing, but the framework also provides its own parsing method (Selector).
- Selector
Xpath
I won’t go into detail here; we can discuss it further when I have time.
At the same time, we need to make slight modifications to the configuration in setting.py (there are many default configurations in setting.py, and here I will only show the modified parts).
# If there is no automatically generated UA, it needs to be defined manually. However, using the same UA for every crawl can easily trigger verification operations, so later I will introduce a method to randomly generate UA.
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
# Allow robots protocol; you can search online for more details about the robots protocol.
ROBOTSTXT_OBEY = False
With this, a simple spider is basically complete. You just need to execute scrapy crawl maoyan (the last part is your spider name).
There are two more key points: one is the persistence of the project, and the other is randomizing the User-Agent.
First, let’s look at persistence. For simplicity, I will demonstrate exporting the spider data in json format.
Here, you need to modify pipline.py. As for why, I believe you can understand after looking at the previous component introduction.
import json
import codecs
class SpiderDemoPipeline:
def process_item(self, item, spider):
return item
class JsonPipline(object):
def __init__(self):
print("Opening file, preparing to write....")
self.file = codecs.open("maoyan.json", "wb", encoding='utf-8')
def process_item(self, item, spider):
print("Preparing to write...")
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def close_spider(self, spider):
print("Writing complete, closing file")
self.file.close
Then, enable the custom pipeline in setting.py.
ITEM_PIPELINES = {
# 'spider_demo.pipelines.SpiderDemoPipeline': 300,
'spider_demo.pipelines.JsonPipline': 200
}
As for randomizing UA, let me first explain the principle of adding UA.
scrapy first reads the UA settings in setting.py, and then goes through middleware. If no custom operations are performed, it will add the UA from the configuration to the request headers. Therefore, to achieve randomization of UA, you can actually manipulate it in the Download Middleware before making the web request.
Here, I modified middleware.py and introduced the third-party package fake_useragent.
from scrapy import signals
import random
from fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
# Randomly change user-agent
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random")
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
def get_ua():
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua())
At the same time, make modifications in setting.py.
DOWNLOADER_MIDDLEWARES = {
'spider_demo.middlewares.SpiderDemoDownloaderMiddleware': 543,
'spider_demo.middlewares.RandomUserAgentMiddleware': 400,
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
}
# Randomly select UA
# This is set by yourself, relying on fake-useragent
RANDOM_UA_TYPE = 'random'
Thus, a simple spider application has been implemented!
You can see that the UA has changed.
At the same time, a maoyan.json file has been generated.