blaze 执行流程源码阅读
首先介绍一下 blaze,blaze 是快手自研的基于 Rust 语言和 DataFusion 框架开发的 Spark 向量化执行引擎,旨在通过本机矢量化执行技术来加速 Spark SQL 的查询处理。为什么考虑深入了解 blaze,首先是因为当前相对成熟的开源 spark…
Karpenter介绍
Karpenter 是一个 AWS 提供的节点生命周期管理器,它会观察传入的 pod 并根据情况启动正确的节点。节点选择决策基于策略并由传入的 pod 的规范驱动,包括资源请求和调度约束。 它的主要作用:
为不可调度的 Pod 启动节点
替换现有的节点提高资源利用率
如果超时…
基于velox的列式shuffle介绍
什么是 velox velox 是一个基于 C++ 编写的开源数据库执行加速工具库。它的优势是利用 native 方法来优化计算,深度利用系统级的优化手段例如向量化技术来加速执行计划。因此,也可以将其称为是一个 native compute engine。将 velox…
Hadoop CommitProtocol介绍
一些笔记的归档。 Hadoop CommitProtocol
hadoop commitProtocol(全称 HadoopMapReduceCommitProtocol)是一套用于用于提交文件到文件系统的规则。是 hadoop 抽象出来的,为了实现存算分离…
spark文件读取分区参数设置方法
简单记录一个 spark 的分区参数如何配置的问题。 最近发现一个案例,线上 EMR 的 spark 在相同 sql 和输入情况比另一个集群的 spark on yarn 要快很多,在排除其他额外因素后,发现 EMR 的任务在开始读取文件的阶段任务数远小于另一个…
CUDA及cudnn初探及安装方法
刚开始玩 stable diffusion, 但用的整合包,很多训练知识都只是一知半解,现学现用,倒也是能炼出一些自己想要的作品。但是最近了解到升级 pyTorch 和 xformer 之后可以极大提高训练 lora 的速度,这不由得让我产生了想升级的念头(刚到手的 4070…
关于S3A的一些踩坑和思考
最近工作中架构升级,将原来的 EMR 集群迁移到基于开源的自建集群上,原来使用的一些组件自然也需要改造,其中就包括 s3。在我们的自建集群中,选用的开源 hadoop 中 s3a client(或者 s3a connector,下面简写成 s3a, 意义基本相同)来连接原有的…
Spark Job长尾问题排查及小文件优化的思考
最近在测试spark on k8s的时候,遇到了一些性能问题,于是记录一下排查过程,做一下案例的复盘。
一些小工具分享...
最近工作的时候接触了一些有意思的东西,这里记录一下,以后或许能用得到。
给Spark添加自定义的metric信息
最近因为一些工作场景需要获取spark 任务的更多信息,所以要修改spark 源码添加新的metric。顺便串一下整个metric体系,形成整体认知。
第一篇博客
想把这里当作一个树洞,聊聊日常,工作,学习和生活。
前段时间因为自己生日,给自己剪了一个视频,让我意识到原来自己还是有不少空余时间。先前因为沉浸在游戏里,感觉时间飞逝而自己又毫无所得,心中不断积累着焦虑,思维也变得怠惰起来。这段时间尝试着克制欲望,多抽出时间来思考,读书…
搭建一个关灯神器
自从租房之后,生活环境发生了很大的变化。其实大部分的变化我尚且还算满意,但每当晚上躺在床上玩手机的时候,当困意袭来时,心里总是非常郁闷:我在这边,灯的开关在床的那边。没办法,只得再度下床关灯,再摸黑爬上床 —— 此时睡意早已消失(大哭 于是,我想到了关灯神器…


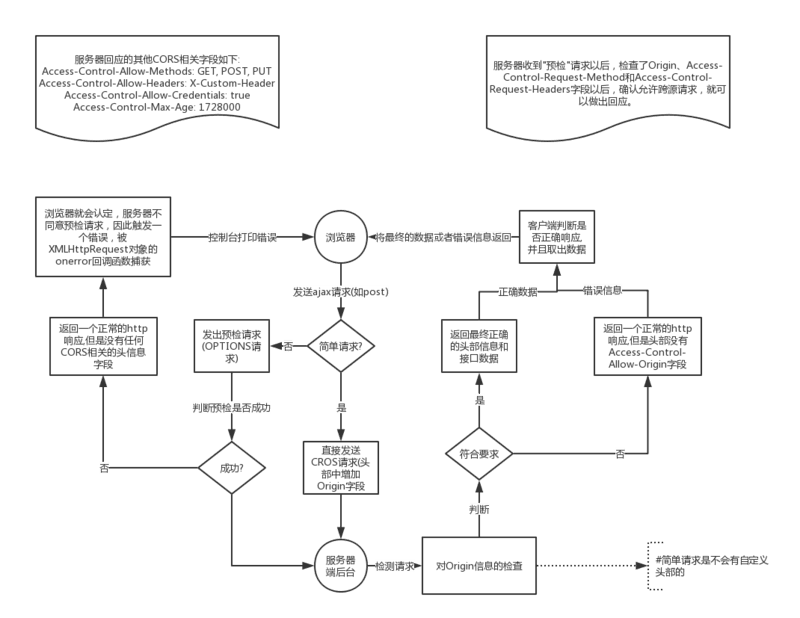


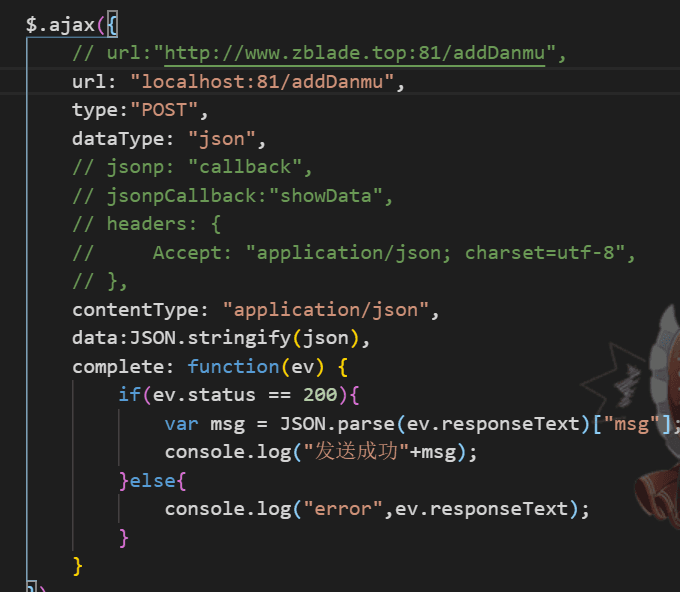
记录一次跨域问题
最近在做前后端交互的时候遇到了特殊的跨域问题。其实自己平时做项目的时候也多多少少处理过跨域问题,但是这次情况特殊。正好借此机会将跨域问题的解决方法做一下总结,以备不时之需。 情景
自己前段时间在学习前端,所以想趁着这个机会自己搞个小工具玩玩…
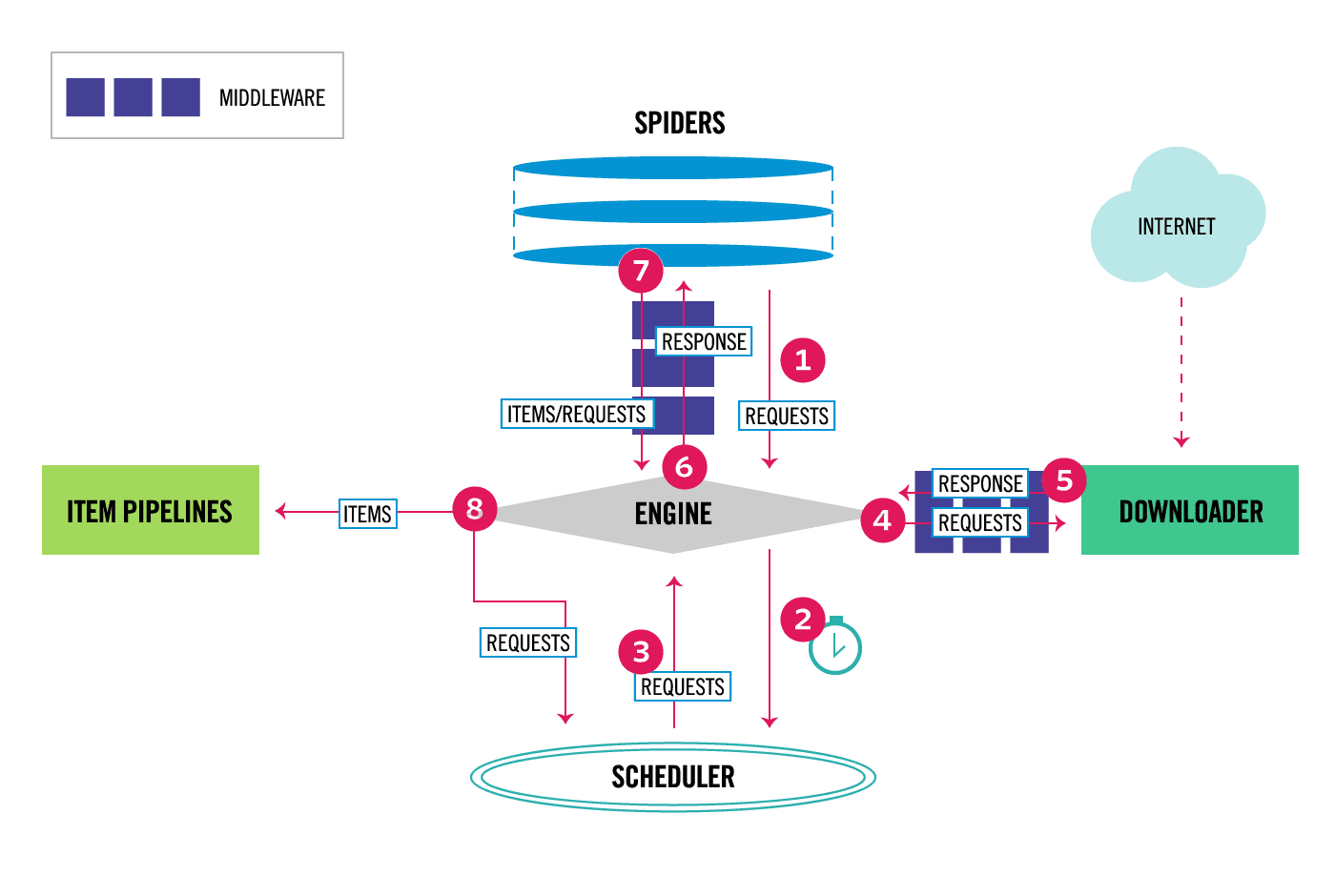
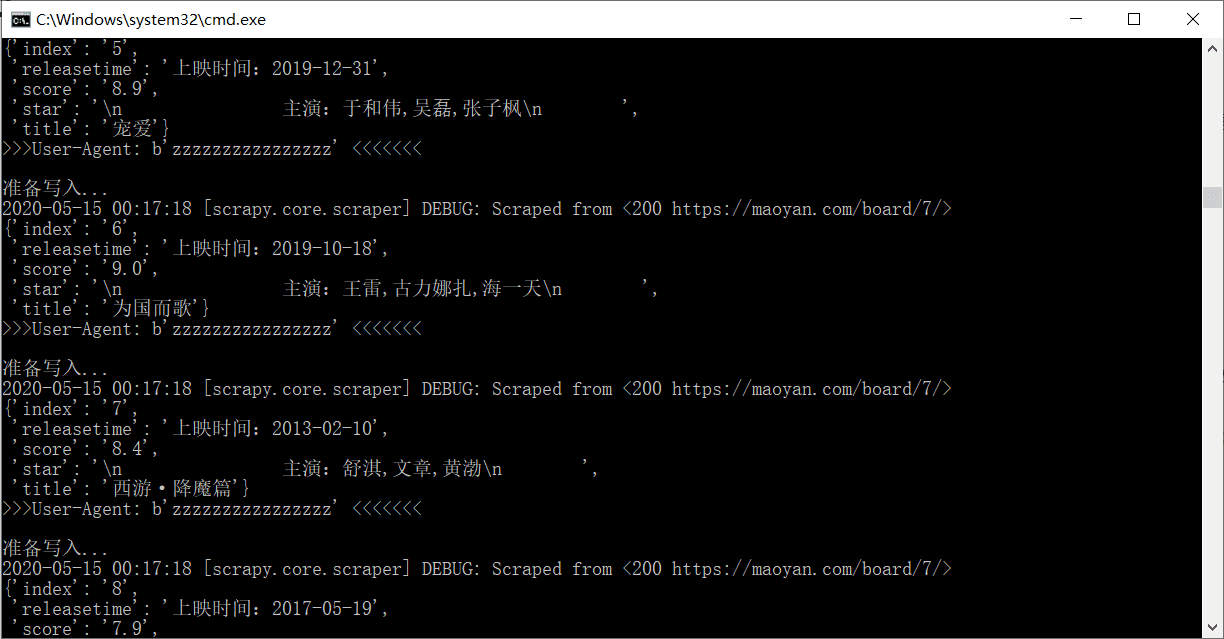
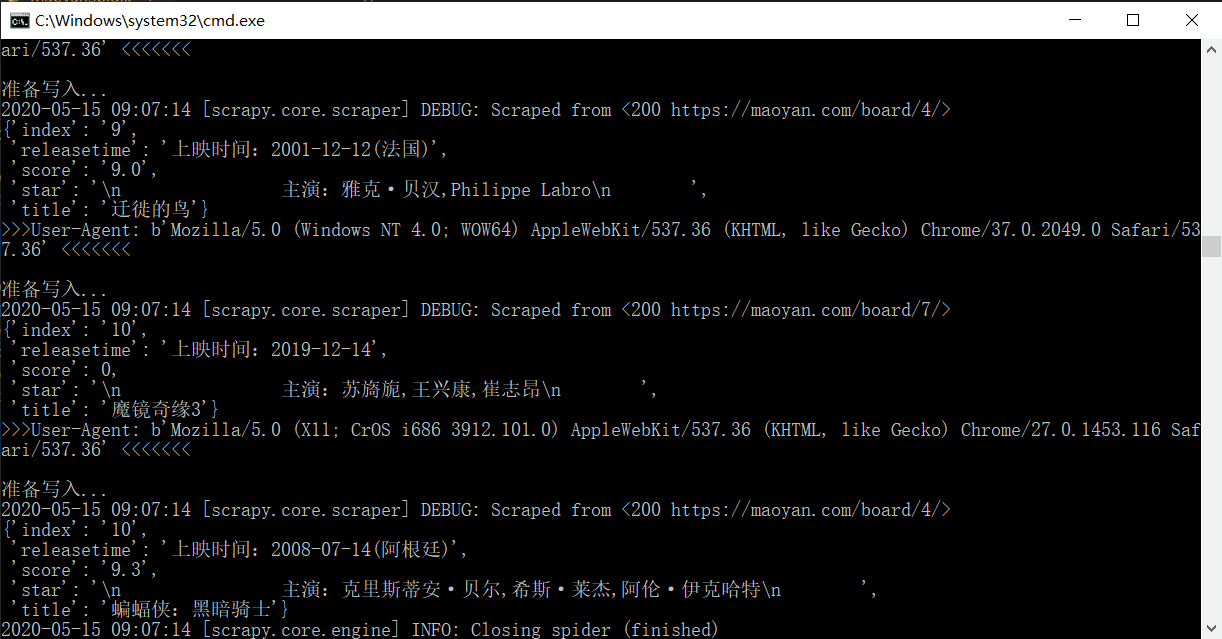
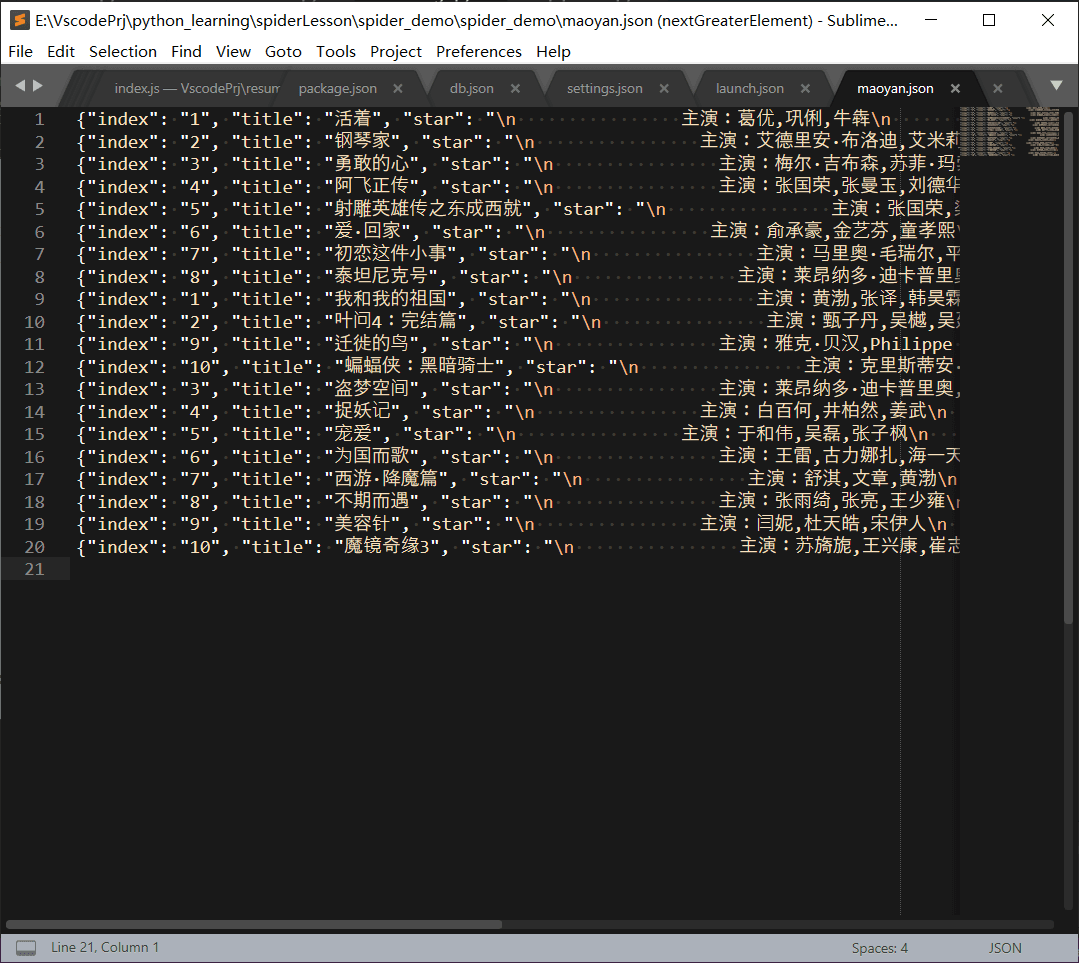
scrapy爬虫入门
现在说到爬虫,大家都会或多或少地将 python 和爬虫联系在一起,归根到底,是因为 python 丰富的生态和灵活简单的语法。同时基于 python 存在有几个强大的爬虫框架,极大地降低了爬虫的难度,提高了编写程序的效率。最近我也体验了一下 scrapy,算是做一个入门的记录吧…

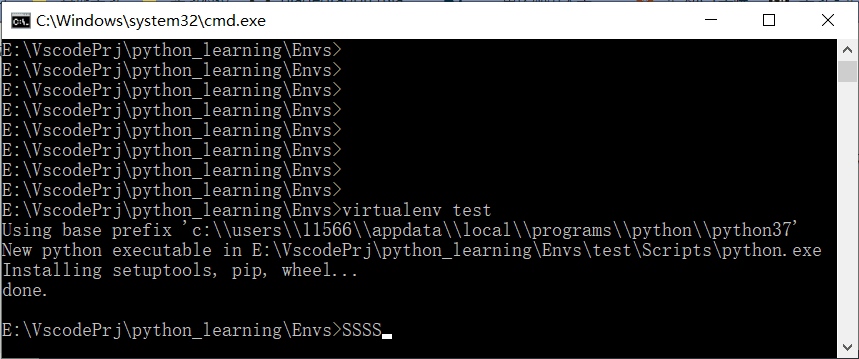
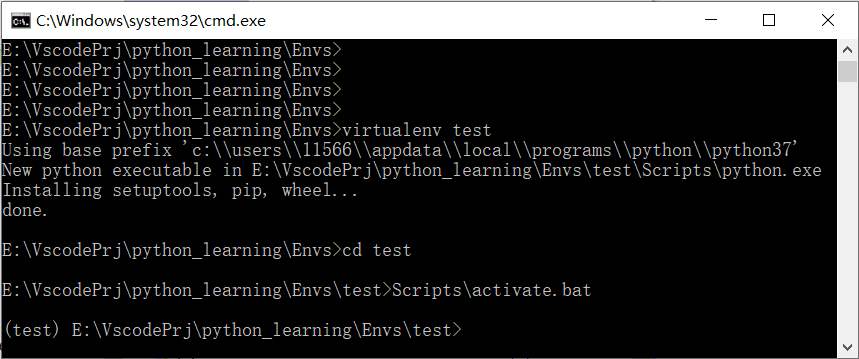
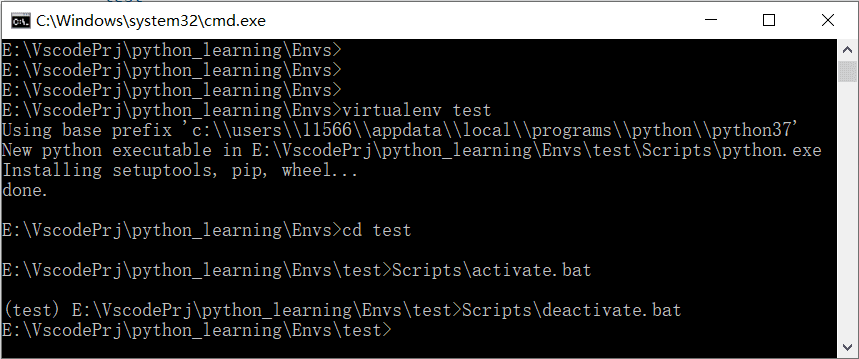
大道至简——virtualenv介绍
python因为丰富的扩展库被大家所青睐,但是当开发环境中的第三方包越来越多的时候,基于该开发环境开发的应用越来越难以移植、迁移。像在操作系统中我们可以用容器(例如docker)将开发环境和生产环境分开,在做 python 的应用开发的时候…
mybatis基础特性和sqlsession原理
主要总结一下 mybaitis 的基础配置,基本特性,最后简单分析一下 sqlsession 的原理,了解了运行过程。 简单配置介绍
简单来说,Mybatis 的配置主要分为以下几步:
编写 POJO 即 JavaBean,最终的目的是将数据库中的查询结果映射到…

《并发编程的艺术》-阅读笔记05:java中的锁
《并发编程的艺术》阅读笔记第五章,图文绝配 你锁我,我锁你,两者互不相让,然后就进入了死局,这像极了爱情。
一、Lock 接口
提供了 synchronized 不具有的特性:
尝试非阻塞地获取锁:tryLock(),调用方法后立刻返回
能被中断地获取锁:lockInter…
《并发编程的艺术》-阅读笔记04:线程间通信
《并发编程的艺术》阅读笔记第四章,重点在于线程间的通信 一、线程简介
首先对线程做一个简单的介绍
使用多线程的原因:
Copy
1.更多的处理器核心:一个线程在一个时刻只能运行在一个处理器核心上
2.更快的响应时间
3.更好的编程模型
JAVA 程序运行所需线程(jdk1…